


Inference-Time Techniques to Improve LLM Reasoning

Large Language Models (LLMs) have revolutionized artificial intelligence by demonstrating unimaginable capabilities in text generation, question answering, and problem-solving. However, their reasoning abilities still face limitations, such as hallucinations, inconsistencies, and difficulties handling complex multi-step problems. While training-time improvements are essential, inference-time techniques offer a more immediate and adaptable solution to enhance LLM reasoning without requiring model retraining.
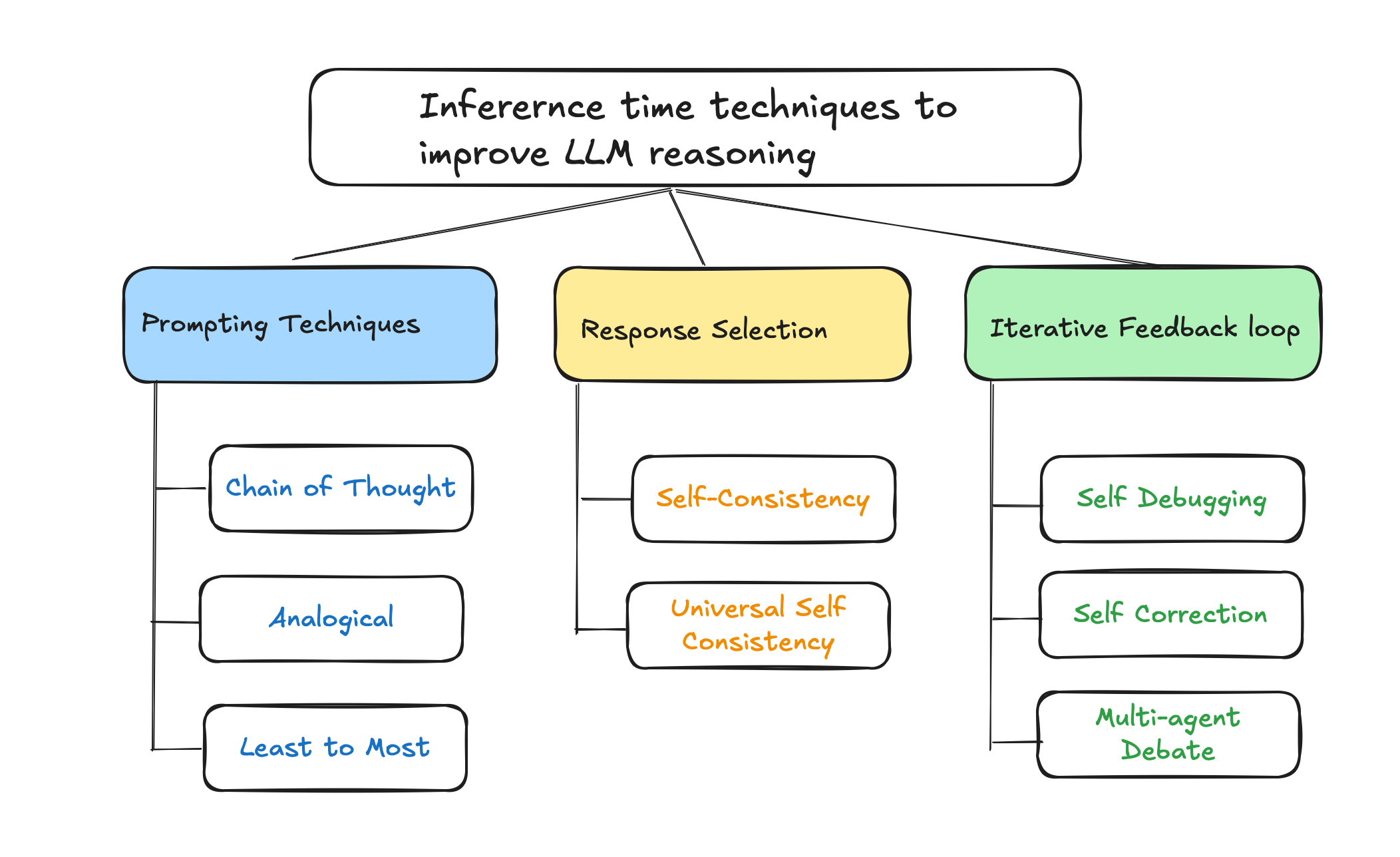
Inference-time techniques refine the way an LLM processes information, ultimately improving response quality, accuracy, and coherence. These techniques can be categorized into three primary approaches:
Prompting Strategies – Enhancing the complexity of prompting and processing within a single response.
Response Selection Strategies – Generating multiple responses and selecting the most optimal one.
Iterative Feedback Loops – Implementing self-evaluation and refinement techniques.
By strategically applying these methods, LLM’s performance in complex reasoning tasks can be improved, making them more reliable for real-world applications. In this article, we explore these techniques in detail and discuss their advantages, limitations, and use cases.
Prompting Strategies: Enhancing Prompt Complexity
Chain-of-Thought (CoT) Prompting
One of the most effective inference-time techniques for improving reasoning is Chain-of-Thought (CoT) prompting. This method encourages LLMs to break down complex problems into intermediate steps, allowing them to generate more structured and accurate responses.
CoT prompting can be implemented in several ways:
Few-shot prompting – Providing exemplars that demonstrate a step-by-step approach.
Instruction prompting – Using direct instructions such as "Let's think step by step."
Zero-shot prompting – Triggering CoT reasoning without examples by instructing the model explicitly.
CoT is particularly effective in mathematical reasoning, logical deduction, and multi-step question answering. However, its success depends on careful prompt engineering, and not all models consistently generate effective reasoning chains. Additionally, longer reasoning chains can increase computational costs.
Analogical Prompting
Analogical prompting enhances reasoning by prompting LLMs to recall and generate relevant analogies before attempting a solution. By drawing parallels between similar problems, the model can apply learned patterns more effectively. This self-generated training data allows the model to adapt its reasoning dynamically, sometimes outperforming manually designed few-shot exemplars.
However, analogical prompting introduces additional complexity, as it requires the model to first generate suitable analogies. If these analogies are weak or misleading, the model's final response may suffer in accuracy.
Least-to-Most Prompting
Least-to-Most (LTM) prompting is another technique that helps models generalize by gradually increasing task complexity. It involves breaking down a problem into simpler subproblems and solving them sequentially:
The model first identifies and solves an easier version of the problem.
The intermediate solution informs the next step, progressively building towards the final answer.
The model combines all intermediate steps to construct a comprehensive solution.
LTM prompting has been highly effective in problem decomposition tasks, making it valuable in mathematics, logical reasoning, and programming challenges. However, its effectiveness depends on well-structured decomposition, which is not always straightforward to define.
Response Selection Strategies: Exploring Multiple Candidates
Self-Consistency
Self-consistency improves LLM reasoning by generating multiple independent responses to the same query and selecting the most consistent answer. This method reduces reliance on a single deterministic outcome and allows the model to explore different reasoning pathways before converging on a solution.
The key benefits of self-consistency include:
Majority consensus – Selecting the most frequently occurring answer enhances accuracy.
Error correction – Incorrect responses are more likely to be filtered out.
Adaptability – The approach scales well with increasing sample sizes.
However, self-consistency requires generating multiple outputs, which increases computational costs. Additionally, ensuring response diversity is crucial—if responses are too similar, the benefits of self-consistency diminish.
Universal Self-Consistency
Universal self-consistency is a variant designed for free-form tasks such as summarization and open-ended reasoning. Unlike traditional self-consistency, which relies on answer extraction, universal self-consistency allows the model to assess coherence among generated responses and select the most logical one.
This technique is particularly useful for subjective or creative tasks where a single correct answer may not exist. However, it remains constrained by an LLM's ability to compare and rank responses effectively.
Iterative Feedback Loops: Refining Through Self-Evaluation
Self-Debugging and Self-Correction
One of the most promising inference-time strategies is self-debugging and self-correction, where the model reevaluates its own outputs and iterates on them to improve accuracy. There are several ways to implement self-correction:
Self-debugging – The model reviews its own outputs and identifies inconsistencies.
Self-correction – The model generates revised responses based on past mistakes.
Multi-agent debate – Multiple instances of an LLM engage in structured debate, refining their responses collaboratively.
While these methods improve response quality, self-correction has limitations. Without external feedback, LLMs may struggle to identify their own errors, leading to incorrect revisions. For instance, a model might mistakenly alter a correct response into an incorrect one if it misjudges its previous output.
Feedback-Enhanced Reasoning
To improve self-correction reliability, feedback mechanisms can be integrated into LLM inference-time processes. These include:
Automated feedback prompts – Asking the model to explain its answer before finalizing a response.
Dynamic re-ranking – Allowing the model to generate multiple responses and rank them based on internal heuristics.
External verifiers – Incorporating external knowledge sources or retrieval-augmented generation (RAG) to cross-check outputs.
These techniques increase computational overhead but provide more reliable and verifiable reasoning.
Summary
Inference-time techniques play a crucial role in enhancing LLM reasoning, offering improvements without requiring retraining. While strategies like CoT, self-consistency, and iterative self-improvement significantly boost performance, they also present challenges, such as token budget constraints and sensitivity to prompt design.
Future advancements in LLM reasoning will likely integrate these methods more effectively, balancing computational efficiency with enhanced decision-making capabilities. By refining inference-time techniques, we can move closer to more reliable and intelligent AI agents that better understand and process complex problems.